
Java 源码学习之java.util.HashMap
HashMap是Java编程中最常用的容器类之一,它是通过数组+链表实现的,在面试时常常被问实现原理以及与HashTable作比较!
HashMap是可以存储键值key-value对的容器,他是基于数组+链表的方式实现的,在遇到数组容量不够时也会执行扩容操作,HashMap具有插入、删除操作几乎为O(1)的效率,但是在迭代器中遍历取值时无法保序,接下来文本将从HashMap的构造、put、remove、iterator等方向进行源码的学习。
私有变量解析
在HashMap的源码中定义的私有变量比ArrayList多很多
1 |
|
咱们现在来讲解几个重要的变量:
DEFAULT_INITIAL_CAPACITY:HashMap的初始化容量默认为16table:HashMap的实际存储容器,可以看出来他是存储在一个键值对的数组中size:HashMap中存储的实际容量threshold:HashMap中当前存储的容量阈值,可在构造函数中初始化,后期在扩容时:threshold=(int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1)loadFactor:负载因子,当loadFactor取的比较小时,可以降低Hash冲突,当时会浪费table的存储空间,但是loadFactor比较大时,会增加Hash冲突概率,导致降低put,remove,get的效率
再来看源码中非常重要的一个类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68static class Entry<K,V> implements Map.Entry<K,V> {
final K key;//键值不可变
V value;
Entry<K,V> next;//实现指针
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
HashMap.Entry是HashMap存储中的核心类,也是存储数组的类型,它从Map.Entry继承而来,HashMap.Entry实际上是一个Key-Value格式存储的实体,也正是因此HashMap支持Key-Value格式的存储,细心的小伙伴可以发现:
final K key:他的键值使用final来修饰,也就是说HashMap存储中的键值是不可变的Entry:他有一个next指针,用于实现HashMap.Entry的列表,HashMap当遇到Hash值冲突时使用建立链表来存储数据
根据上述我们可以知道HashMap的存储结构图如下: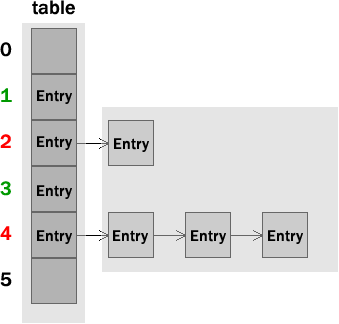
HashMap使用Entry类型的数组进行存储- 当
Entry的Hash值冲突时,将已存在的相应桶号(hash值)上的Entry后添加链表的方式进行存储
构造函数
1 | /** |
- 指定初始容量和负载因子
- 制定初始容量
- 直接使用map容器实体来构造
这三种构造函数,其中的指定初始容量和负载因子均不能小于等于0,并且负载因子必须是float类型的
hash散列
HashMap通过自定义的hash函数希望将各个key均匀得分散到各个桶中
1 | /** |
上面hash的源码中我们可以了解到:
- 当
hashSeed!=0和key为String类型时,将使用sun.misc.Hashing.stringHash32((String) k)进行hash,否则主要使用无符号位移位和异或操作得到hash值 - 当
key=null的时候得到的hash值为0 HashMap的table的length必须为2的幂次方,在indexFor方法中通过hash值和length-1的与操作来得到桶号,保证获取的桶号小于尺寸阈值,这个桶号的是否均匀很重要,假如t为奇数,则length-1为偶数,二进制的最低位肯定为0,在与hash值进行与操作之后得到的最低位肯定也为0,则最终得到到桶号一定是偶数,这样的话indexFor方法将一定返回偶数,也就是说HashMap存储数组中的奇数索引位置都不会存储值,这会大大浪费存储空间,同时会增加hash冲突的概率,然而当length为偶数时,length-1的最低位为1,与hash值进行与操作时候得到的奇偶数概率各一半,这样就可以均匀的散列到各个桶中了
put方法
put方法是HashMap最常用的一个方法,它传递一组key-value数据往HashMap中添加,如果key存在,则更新该key的value,但是你知道put方法整个实现的流程吗?特别是在hash冲突时!
1 | /** |
上面put过程中涉及到几个重要方法的说明:
put:HashMap对外开放的接口方法,如果已存在key的键,进行更新操作,返回oldValue,否则调用addEntry进行插入,返回nullinflateTable:初始化的空的tableputForNullKey:插入或者更新键为null的值,如果已存在null的键,进行更新操作,返回oldValue,否则调用addEntry进行插入,返回nulladdEntry:添加Entry实体,会进行size >= threshold判断,如果成立,触发resize进行扩容,最终会调用createEntry插入key-valuecreateEntry:将key-value插入table[buctetIndex]的表头(这样做在插入的时候就不需要判断原来的链表上是否有值了,bingo)resize:进行扩容操作,扩容完成之后容量为原来的2倍,同时会调用transfer进行rehashtransfer:根据原来的key和新的length进行rehash,得到新的table
将上述执行流程使用图来表示之后: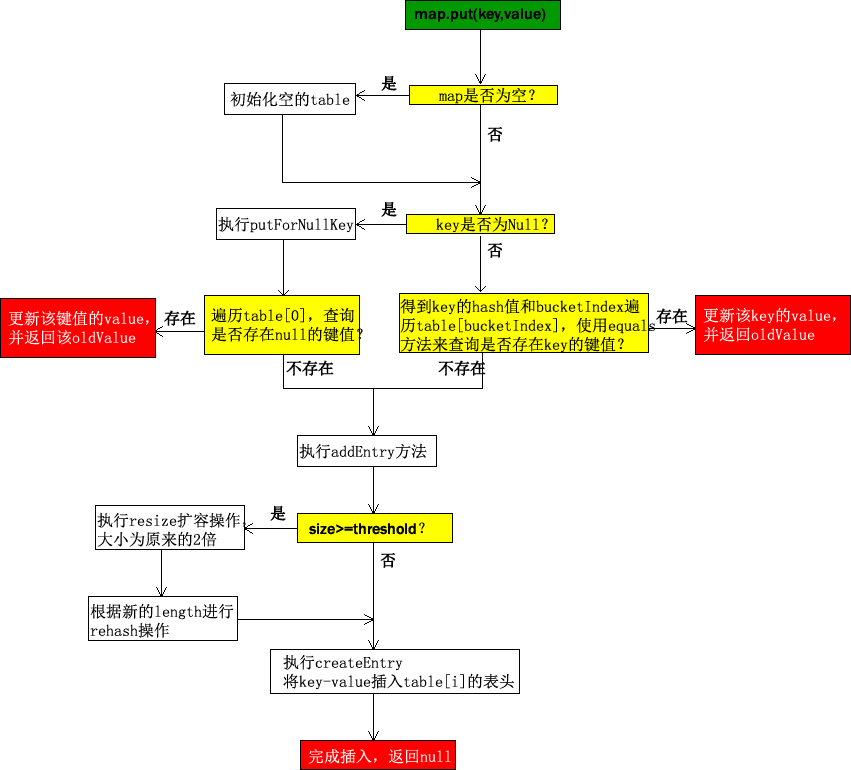
remove方法
remove是HashMap中最长用的方法之一,他是通过链表进行删除的
1 | /** |
remove方法比较简单,首先是得到删除key的hash值和其对应的桶号i(key=null时其桶号为0),根据其i即可取得所在的单链表,然后循环单链表,通过equals来查找是否存在对应的key,如存在,则在单链表上删除key所对应的Entry,将删除的Entry进行返回,否则返回null
get和containsKey方法
我们常常会先执行
containsKey来判断HashMap中是否存在所查询的key值,如存在再进行get,那这两个方法实现上是?
1 | /** |
有没有惊奇的发现get和containsKey最终都会调用getEntry方法,只是在返回值上作了不同的判断而已,getEntry方法是根据key通过遍历链表来获取对应的Entry实体。另外get在同前面一样在null上也是作了单独的处理。
keySet和values集合
在遍历
HashMap取值时主要有:
- keySet:取得键集合,迭代键集合通过
get方法逐个取值- values:直接取得
HashMap的value集合进行遍历
下面我们看下这两个方法在源码中的实现
keySet方法的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46/**
* Returns a {@link Set} view of the keys contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation), the results of
* the iteration are undefined. The set supports element removal,
* which removes the corresponding mapping from the map, via the
* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>
* operations.
*/
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
// Subclass overrides these to alter behavior of views' iterator() method
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
private final class KeyIterator extends HashIterator<K> {//最终还是基于HashIterator迭代器
public K next() {
return nextEntry().getKey();
}
}
values方法的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42/**
* Returns a {@link Collection} view of the values contained in this map.
* The collection is backed by the map, so changes to the map are
* reflected in the collection, and vice-versa. If the map is
* modified while an iteration over the collection is in progress
* (except through the iterator's own <tt>remove</tt> operation),
* the results of the iteration are undefined. The collection
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Collection.remove</tt>, <tt>removeAll</tt>,
* <tt>retainAll</tt> and <tt>clear</tt> operations. It does not
* support the <tt>add</tt> or <tt>addAll</tt> operations.
*/
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
private final class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
Iterator<V> newValueIterator() {
return new ValueIterator();
}
private final class ValueIterator extends HashIterator<V> {//最终还是基于HashIterator迭代器
public V next() {
return nextEntry().value;
}
}
通过上面keySet和values这两个方法的源码会发现他们最终都是调用HashIterator来进行实现的,只是keySet通过HashIterator迭代器之后返回的是Entry的key,而values返回的是Entry的value1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)//一直循环到有值的Entry作为起始的Iter起点
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
HashIterator在实现时主要解决的时缺省问题,因为HashMap的table是根据散列码来存储的,并不是连续的,在进行迭代的时候需要隔离开这些不连续的数据,在HashIterator中是靠while (index < t.length && (next = t[index++]) == null)进行不连续缺省值的判断的。
HashMap的复杂度
如果说HashMap的get,put,remove方法的复杂度是O(1),大多数程序都应该会认同吧?其实看了上面的源码之后说O(1)的并不准确,执行这三个方法他们都要做的一件事情就是遍历桶号所在的链表,进行已有key的判断,当这个链表的长度为0或者为1时,自然的他们的复杂度都是O(1),那是在没有hash冲突的情况下,但是假如存在hash冲突,那么必然两个不同的key会散列到同一个链表中,其实他们的复杂度就不是O(1)了,所以我觉得比较安全的说法是这三个方法的复杂度近似为O(1)。
关于HashMap的优化,就是需要减少hash冲突,越少越好,我们知道table的容量越大,hash冲突的概率会越低,但是table的利用率也会越低,所以table的容量至关重要,我们也知道size>=table.length*loadFactor时,table就会扩容量,所以我们在优化loadFactor参数很重要。
总结
HashMap不是线程安全的类HashMap是基于数组加链表的形式实现的HashMap支持null键和值HashMap在size>=table.length*loadFactor时会进行2倍扩容HashMap的get,put,remove复杂度近似O(1)loadFactor是优化的重要参数,loadFactor越大,hash冲突的概率越大,table的利用率越大,反之都越小
本作品采用[知识共享署名-非商业性使用-相同方式共享 2.5]中国大陆许可协议进行许可,我的博客欢迎复制共享,但在同时,希望保留我的署名权kubiCode,并且,不得用于商业用途。如您有任何疑问或者授权方面的协商,请给我留言。
